Последний экзамен: тест, который ИИ проваливает
Авторы: Center for AI Safety, Scale AI

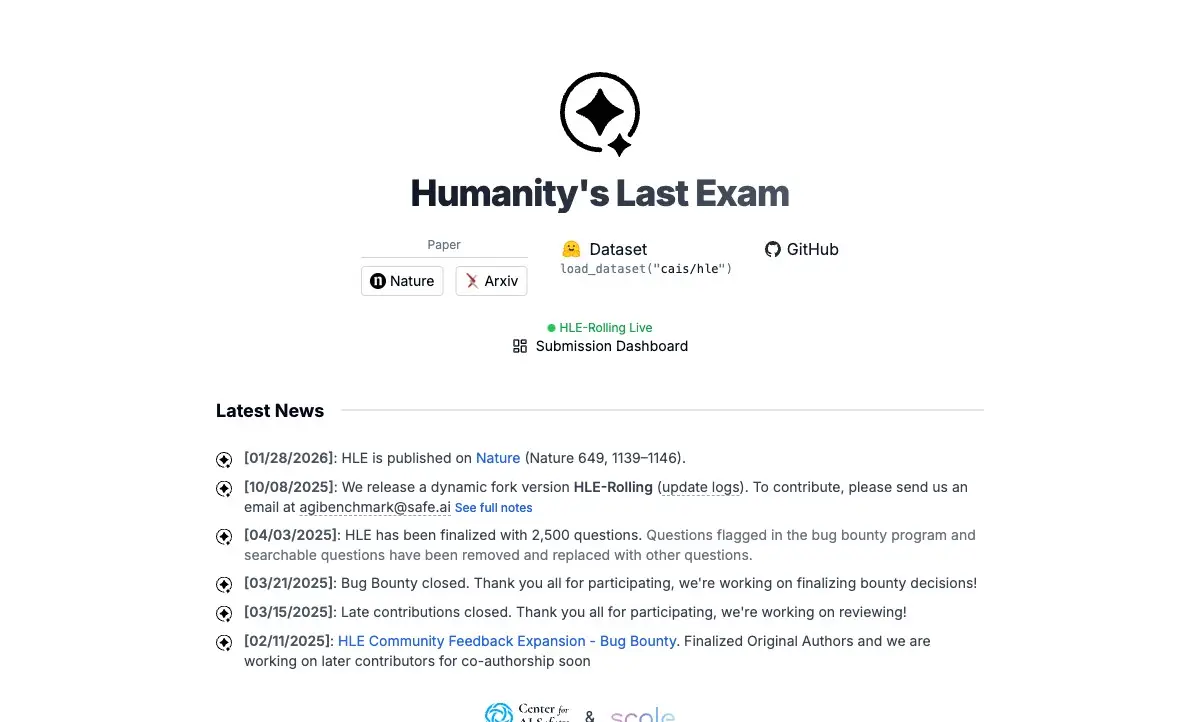
GPT-4o — 2,7%. Claude 3.5 Sonnet — 4,1%. OpenAI o1 — 8%. Человек-эксперт — около 90%.
Это не баги. Это результаты одного и того же экзамена: Humanity’s Last Exam, или HLE. Тысяча исследователей со всего мира создали набор из 2 500 вопросов, на которые не ответит ни одна современная нейросеть. Тест опубликован в Nature в январе 2026 года — и к марту ни одна модель не набрала даже половины.
2 500 вопросов, которые не гуглятся
Бенчмарк — стандартизированный тест для оценки ИИ-систем. Самый известный — MMLU (57 предметов, множественный выбор). Проблема: топовые модели уже набирают 90%+ на MMLU, и тест перестал различать сильных от сильнейших.
HLE задумывался как бенчмарк, который переживёт это. Организаторы — Center for AI Safety и Scale AI — пригласили почти 1 000 экспертов: математиков, химиков, лингвистов, историков, программистов. Каждый должен был предложить вопросы из своей узкой области — такие, чтобы ответ нельзя было найти поиском. Пальмирские надписи. Микроанатомия птиц. Произношение библейского иврита. Квантовая химия переходных металлов.
Ключевой фильтр: если хотя бы одна из топовых моделей отвечала правильно на этапе отбора — вопрос выбрасывали. HLE по определению содержит только то, что текущие ИИ-системы не могут решить.
Результат — 2 500 вопросов с единственным однозначным ответом. Все закрытые, все проверяемые. Никаких эссе, никакой субъективности. Либо знаешь — либо нет.
От пальмирских надписей до квантовой химии
Что делает HLE таким сложным? Не математика сама по себе — GPT-5 решает олимпиадные задачи. Не программирование — Codex пишет рабочий код. Дело в пересечении глубокой экспертизы и редких знаний.
Один из авторов, Тунг Нгуен из Texas A&M, написал 73 вопроса — второй результат по количеству. Большинство из области математики и информатики. «Интеллект — это не распознавание паттернов, — объясняет он. — Это глубина, контекст и специализированная экспертиза».
Типичный вопрос HLE требует: знать факт, который известен нескольким сотням людей в мире; применить к нему рассуждение из смежной области; выдать точный, верифицируемый ответ. Ни один из этих шагов не выполняется поиском по интернету — потому что ответы не существуют в открытом виде.
Табло, которое никто не хотел видеть
Когда HLE запустили в конце 2025 года, результаты шокировали даже скептиков.

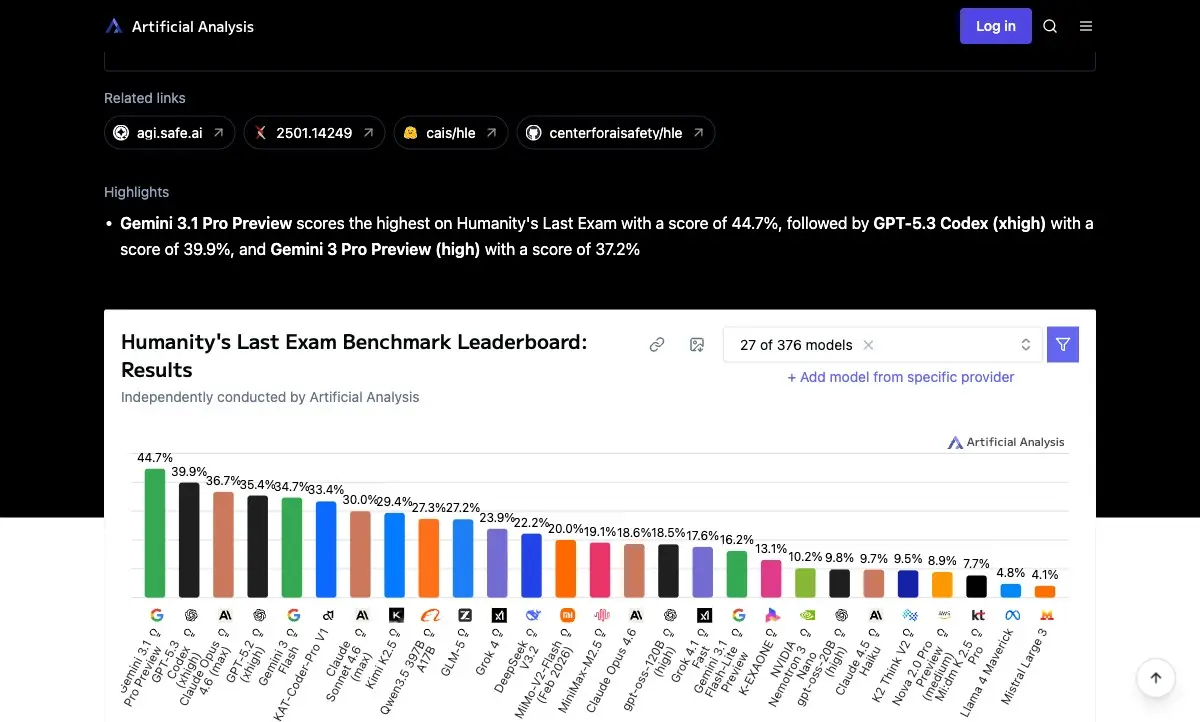
Рис. 1: Результаты моделей на HLE по данным Artificial Analysis (март 2026). Лучший результат — 44,7% (Gemini 3.1 Pro Preview). Ранние модели набирали менее 10%. Источник: Artificial Analysis
Первые участники — GPT-4o (2,7%) и Claude 3.5 Sonnet (4,1%) — выглядели хуже генератора случайных ответов. Даже o1, специально обученная для рассуждений, набрала только 8%. Человеческие эксперты на тех же вопросах показывали около 90%.
К марту 2026 года новые модели подтянулись. Gemini 3.1 Pro Preview — 44,7%. GPT-5.3 Codex — 39,9%. Но это всё ещё провал: меньше половины. А ведь для включения в тест вопрос должен был заваливать все модели на момент создания — то есть бенчмарк буквально запроектирован быть нерешаемым.
Почему нейросети не справляются
HLE бьёт по трём слабым местам одновременно. Первое — редкие знания. Модели обучены на интернете, а многие ответы HLE просто не встречаются в интернете. Они живут в головах нескольких десятков специалистов, в неоцифрованных книгах, в устной академической традиции.
Второе — многошаговое рассуждение через домены. Вопрос может начинаться в минералогии, проходить через термодинамику и заканчиваться в истории химии. Языковые модели хорошо рассуждают внутри одного домена, но теряют нить на стыках.
Третье — калибровка. Модели не просто ошибаются — они ошибаются уверенно. На вопросах HLE нейросети часто дают ответ с уверенностью 90–100% — и оказываются неправы. Этот феномен называют «уверенные галлюцинации», и HLE обнажает его как никакой другой тест.
Когда 30% «правильных» ответов — неправильные
HLE не обошёлся без скандала. Независимый анализ FutureHouse показал: около 30% ответов в секциях биологии и химии содержали ошибки. Автор вопроса сам указывал «правильный» ответ, а рецензентам давали около пяти минут на проверку задачи аспирантского уровня. Этого мало.
Из-за этого нейросеть может дать верный ответ и получить «неправильно», потому что ключ ошибочен. Критики прямо называют HLE «total joke» и предлагают радикальную переработку. Организаторы ответили: создали «золотые» поднаборы (Bio/Chem Gold), где каждый вопрос проверяют несколько экспертов и отдельные ИИ-верификаторы.
Вторая линия критики: значительная часть вопросов — это не проверка мышления, а академическая тривия. Знание самого редкого благородного газа в земной коре или произношения конкретного слова на мёртвом языке — это не интеллект. Это память. А проверять память у системы, обученной на корпусе текстов, — сомнительная затея.
Статья опубликована в Nature (том 649, стр. 1139–1146) в январе 2026 года и прошла рецензирование.
Зачем нам тест, который никто не может сдать
При всех проблемах, HLE сделал видимым важный разрыв: между тем, что ИИ кажется способен делать, и тем, что он действительно знает. На привычных бенчмарках модели набирают 90%+, и легко поверить, что до «настоящего» интеллекта осталось чуть-чуть. HLE показывает: разрыв огромен.
Создатель бенчмарка сам предсказывал, что HLE «не проживёт и года» — ожидая появления сверхчеловеческих математиков-ИИ к 2025. Год прошёл. Лучший результат — 44,7%. Экзамен жив, и это само по себе — результат.
Бенчмарки — не экзамены. Они не ставят оценку. Они измеряют расстояние: от того, где ИИ сейчас, до того, где мы хотим его видеть. HLE отмерил это расстояние честнее, чем что-либо до него — пусть и с 30% ошибок в ключах.
Источники
Оригинал
Связанные
Читайте также


ИИ просканировал 67 000 магнитов и нашёл 25 альтернатив без редкоземельных элементов
Физики из Университета Нью-Гэмпшира создали крупнейшую ИИ-курируемую базу магнитных материалов и обнаружили 25 высокотемпературных магнитов, способных заменить редкоземельные элементы в электромобилях.

SleepFM: ИИ предсказывает 130 болезней по одной ночи сна
Stanford обучил нейросеть на 585 000 часах сна. Она видит Паркинсон, деменцию и рак за годы до симптомов — по обычной полисомнографии.


«Большая пятёрка» 2.0: гены, стресс и смертность в науке о личности
Обзор семи ключевых исследований 2024–2025 годов: от 254 генов личности до «шестого фактора», от IL-6 как биомаркера смертности до влияния стресса на характер.