ENIGMA: чтение мыслей за 15 минут через ЭЭГ
Авторы: Reese Kneeland, Wangshu Jiang, Ugo Bruzadin Nunes, Paul Steven Scotti, Arnaud Delorme, Jonathan Xu

Зачем это важно
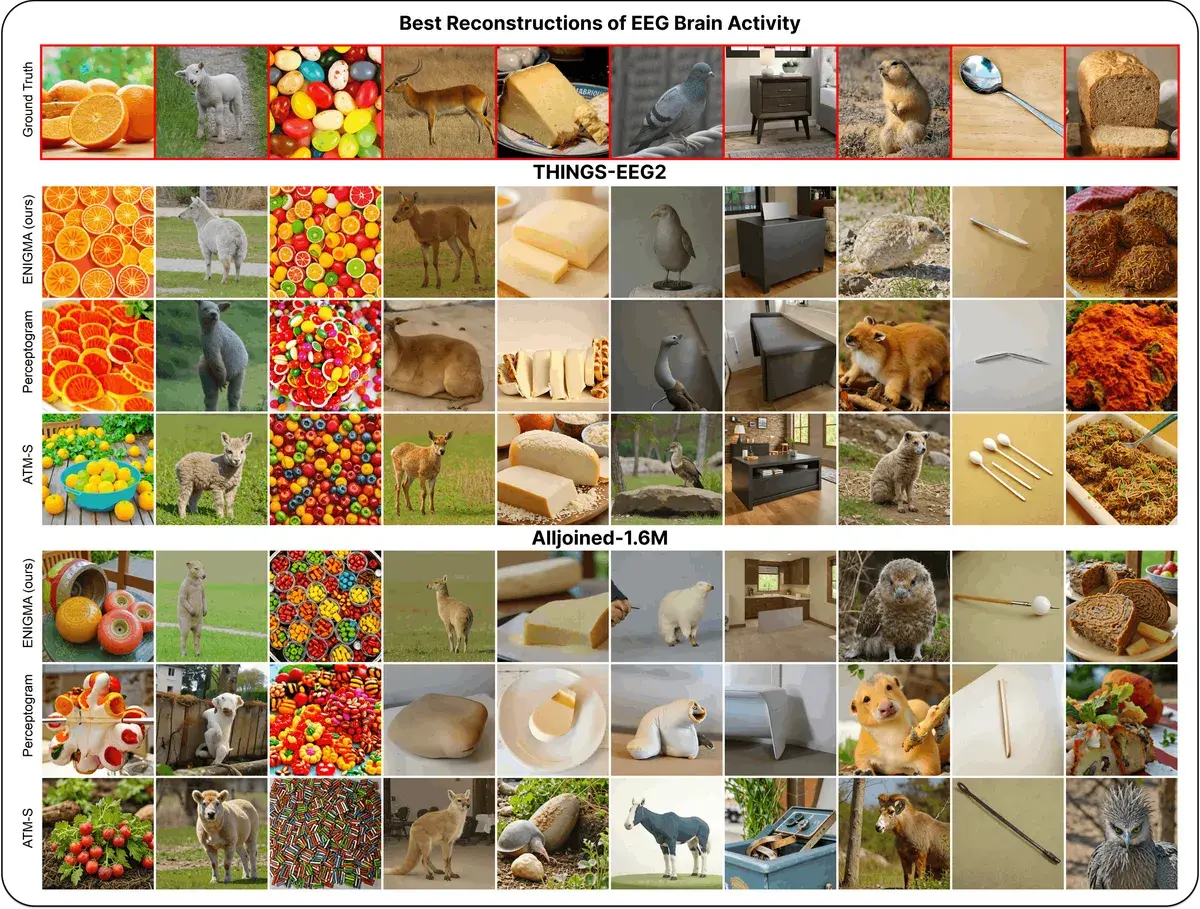
Представьте: вы надеваете компактную гарнитуру с электродами, смотрите на экран 15 минут — и после этого компьютер может буквально видеть то, что видите вы. Не размытые пятна, а узнаваемые изображения: апельсины, овец, мебель, лица.
Звучит как научная фантастика, но именно это продемонстрировала команда исследователей в работе ENIGMA. И самое интересное — для этого не нужен МРТ-сканер за десятки тысяч долларов. Достаточно ЭЭГ-гарнитуры, которую можно купить онлайн.
Основная идея
ENIGMA — это модель, которая восстанавливает изображения из электрической активности мозга, записанной через ЭЭГ (электроэнцефалографию).
ЭЭГ (электроэнцефалография) — метод записи электрической активности мозга через электроды на поверхности головы. В отличие от МРТ, не требует громоздкого оборудования и может использоваться в повседневных условиях.
Три прорыва отличают ENIGMA от всех предыдущих подходов:
-
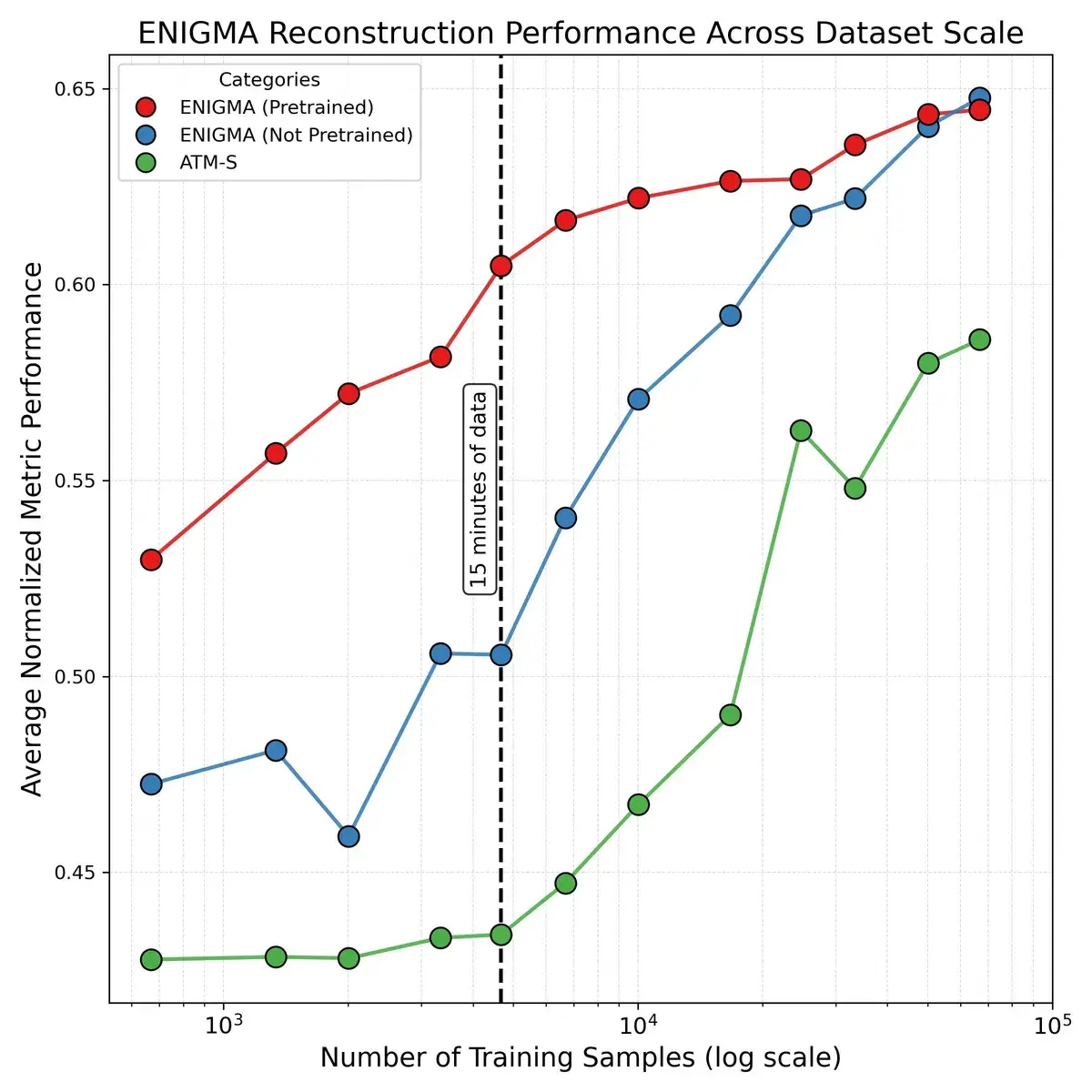
15 минут вместо часов. Предыдущие системы требовали часы данных для каждого нового пользователя. ENIGMA достигает лучших результатов после 15-минутной калибровки.
-
Менее 1% параметров. Модель в 165 раз компактнее конкурентов при обслуживании 30 пользователей одновременно — это делает реальной работу на обычных устройствах.
-
Работает с дешёвыми датчиками. Конкуренты ломаются на потребительских ЭЭГ-гарнитурах ($2200). ENIGMA сохраняет работоспособность.
Как это работает

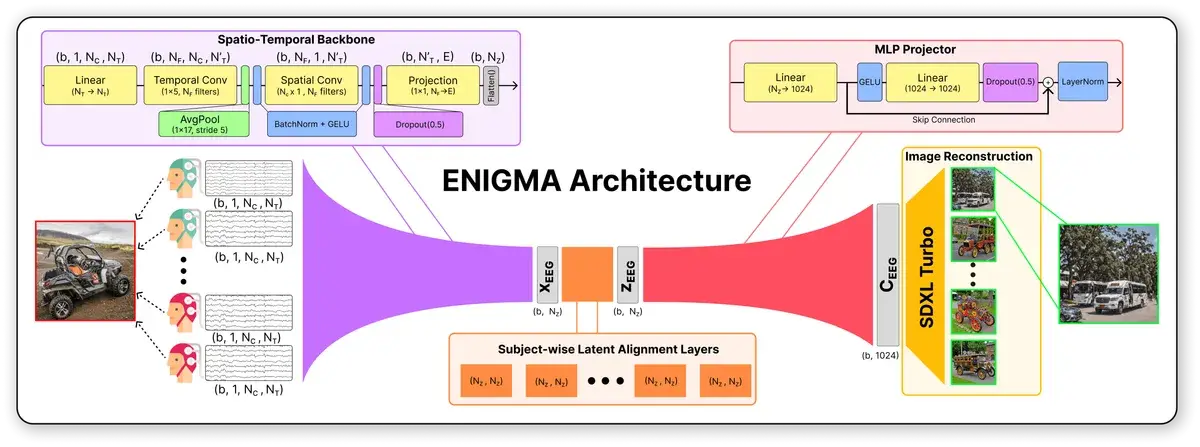
Архитектура ENIGMA состоит из четырёх последовательных блоков:
1. Пространственно-временной backbone. Сырой сигнал ЭЭГ (каналы x временные точки) обрабатывается как двумерная «картинка». Временные свёртки улавливают паттерны во времени, пространственные — связи между электродами. На выходе — компактный вектор из 184 чисел.
Backbone — основная «хребтовая» часть нейросети, которая извлекает ключевые признаки из входных данных. Все остальные компоненты строятся поверх неё.
2. Индивидуальные слои выравнивания. Мозг каждого человека генерирует сигналы немного по-разному. Вместо отдельной модели для каждого, ENIGMA добавляет крошечный персональный слой (184×184 весов) — это и есть секрет экономии параметров.
3. MLP-проектор. Преобразует 184-мерный вектор мозговой активности в 1024-мерное пространство CLIP — универсального представления визуальной информации.
CLIP — модель от OpenAI, которая «понимает» связь между изображениями и текстом. Работает как общий язык между зрением и мышлением для ИИ.
4. Генератор изображений. Stable Diffusion XL Turbo превращает вектор CLIP в финальное изображение всего за 4 шага диффузии.
Ключевая находка: авторы отказались от нормализации целевых CLIP-векторов в функции потерь (в отличие от конкурентов), что сохраняет геометрию пространства представлений и устраняет необходимость в отдельном «диффузионном приоре».
Результаты

Модель протестирована на двух наборах данных:
- THINGS-EEG2 — исследовательская аппаратура за ~$60 000, 64 канала, 1000 Гц
- AllJoined-1.6M — потребительская гарнитура за ~$2 200, 32 канала, 250 Гц
| Метрика | ENIGMA | ATM-S (конкурент) | Perceptogram |
|---|---|---|---|
| Точность CLIP | 80,3% | 55,0% | — |
| Распознавание людьми | 86,0% | 56,8% | — |
| Параметры (30 чел.) | 2.4M | 384M | 4 700M |
На потребительском оборудовании (AllJoined-1.6M) ENIGMA набирает 70,7% точности распознавания людьми, тогда как ATM-S — всего 52,2%.
Человеческая оценка. 545 добровольцев участвовали в слепом тестировании: им показывали оригинал и две реконструкции, и просили выбрать более похожую. ENIGMA побеждала во всех условиях.

Критический взгляд
Работа является препринтом и ещё не прошла формальное рецензирование.
Главные достижения ENIGMA находятся на пересечении научной новизны и практической значимости. Это первая система, продемонстрировавшая конкурентоспособное качество декодирования на потребительском ЭЭГ-оборудовании — различие принципиальное, поскольку все предыдущие методы молчаливо предполагали наличие исследовательской аппаратуры. Сжатие многопользовательской модели до 2,4 миллиона параметров (в 165 раз меньше ближайшего конкурента) — это не просто инженерное достижение: оно определяет разницу между системой, которая живёт в серверной стойке, и той, что способна работать на ноутбуке. Не менее важна поведенческая валидация: 545 человек-судей в слепом тестировании выводят результаты за пределы самореференциального мира автоматических метрик. Авторы также берут обязательство по воспроизводимости: модель работает на потребительских GPU с 8 ГБ VRAM, код обещан к публичной публикации.
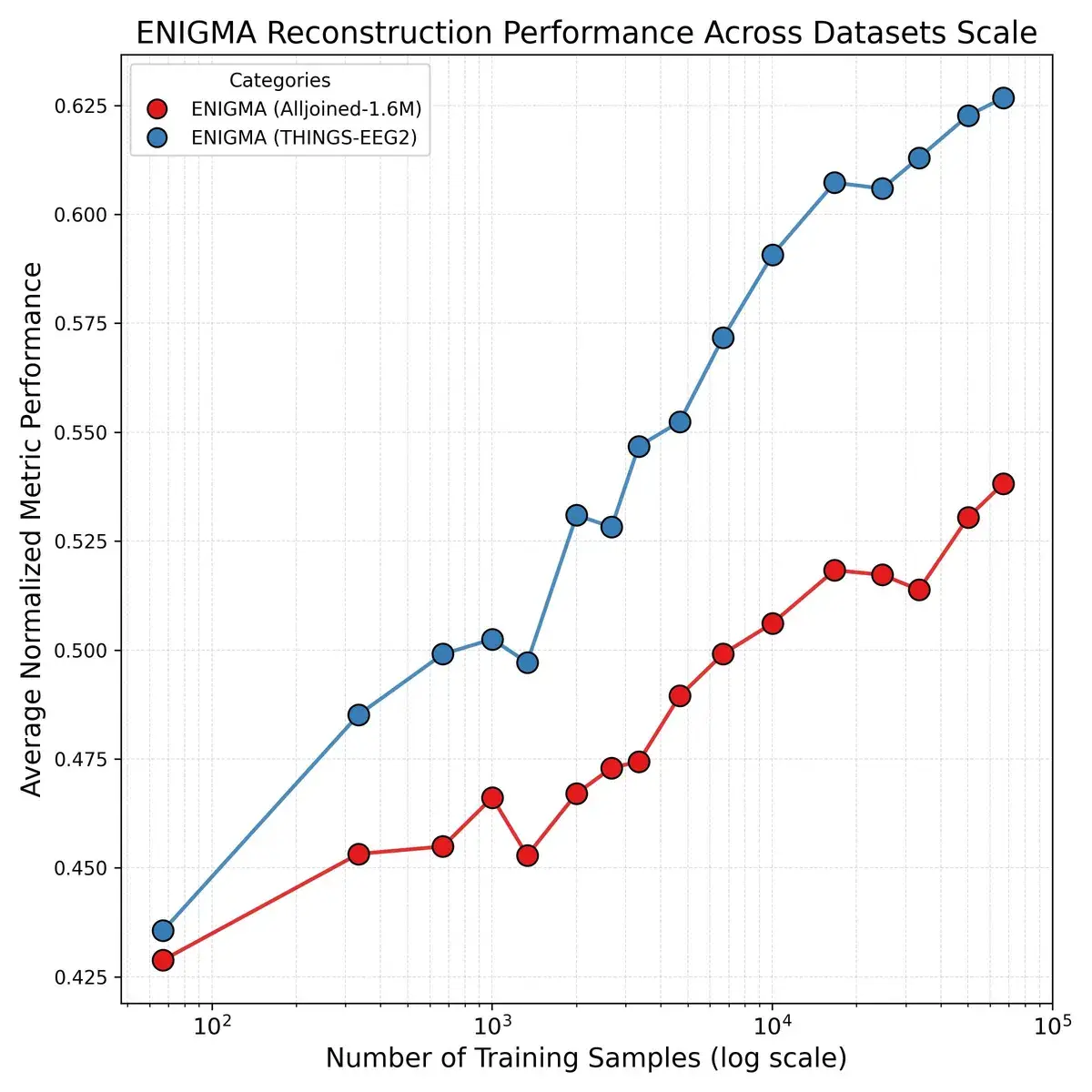
Ограничения реальны и заслуживают честного разговора. Добавление новых пользователей в обучение не поднимает потолок качества модели: масштабирование по субъектам улучшает обобщение, но не пиковые результаты. Это говорит о том, что архитектура, возможно, упирается в фундаментальный предел того, что поверхностная ЭЭГ вообще способна кодировать. Всё тестирование проводилось в единственной узкой парадигме — рассматривании статичных изображений из датасета THINGS, — и остаётся неизвестным, как ENIGMA покажет себя в других BCI-задачах: декодировании воображаемой речи, двигательных представлениях или распознавании эмоциональных состояний. И хотя результат на потребительском оборудовании впечатляет, разрыв между исследовательским ($60 000) и бюджетным ($2 200) датчиком по-прежнему виден в цифрах.
Наиболее глубокий открытый вопрос — способна ли модель декодировать мысленные образы: изображения, существующие исключительно в уме, без внешнего стимула. Это было бы качественно иной возможностью, и в текущей работе она не рассматривается. Рядом с технологической границей располагается этическая: система, которая восстанавливает визуальный опыт из мозговых сигналов с точностью 86% по человеческой оценке, работающая на недорогом оборудовании, — это уже не отдалённая гипотеза. Авторы сами призывают к разработке этического фреймворка для регулирования её применения. Этот фреймворк пока не существует — и его создание, вероятно, окажется сложнее, чем создание самой модели.
Выводы
ENIGMA — это шаг от лабораторных демонстраций к реальным интерфейсам «мозг-компьютер». Когда для декодирования визуального опыта достаточно 15 минут калибровки и гарнитуры за $2200, технология перестаёт быть игрушкой для нейроучёных.
Но вместе с возможностями приходят и риски. Авторы честно признают: способность читать визуальный опыт из мозговой активности требует жёстких этических рамок — для защиты приватности, прозрачности и ответственного использования. Пока таких рамок нет, каждый шаг вперёд в «чтении мыслей» — это одновременно и надежда, и предупреждение.
Читайте также

SleepFM: 130 болезней по одной ночи сна
Stanford обучил нейросеть на 585 000 часах сна. Она видит Паркинсон, деменцию и рак за годы до симптомов — по обычной полисомнографии.

75 000 прогнозов за матч: ИИ в футболе
Нейросеть на базе Axial Transformer от Stats Perform генерирует 75 000 прогнозов за футбольный матч с задержкой менее секунды


CDG-2: галактика из 99% тёмной материи
Галактика CDG-2 состоит на 99% из тёмной материи. Её нашли по четырём шаровым скоплениям — впервые в истории.