Humanity's Last Exam: The Test AI Keeps Failing
Authors: Center for AI Safety, Scale AI

GPT-4o scored 2,7%. Claude 3.5 Sonnet managed 4,1%. OpenAI’s reasoning model o1 reached 8%. Human experts on the same questions? Around 90%.
Those numbers come from Humanity’s Last Exam — a benchmark built by nearly 1,000 researchers worldwide, published in Nature in January 2026. The premise: create 2,500 questions so deeply rooted in expert knowledge that no current AI system can pass. By March 2026, the best model still hasn’t cracked 45%.
An Exam Designed to Break AI
Benchmark — a standardized test for evaluating AI systems. The most famous is MMLU (57 subjects, multiple choice). The problem: top models already score above 90% on MMLU, so the test no longer separates strong from strongest.
HLE was meant to outlast that saturation. The Center for AI Safety and Scale AI recruited experts from every corner of academia — mathematicians, chemists, linguists, historians, computer scientists. Each contributed questions from their narrow specialty, chosen specifically because the answers cannot be found through internet search. Palmyrene inscriptions. Microanatomy of bird species. Biblical Hebrew pronunciation. Transition metal quantum chemistry.
The critical filter: if any frontier model answered a question correctly during the selection phase, that question was thrown out. HLE contains, by construction, only what current AI cannot solve.
The result: 2,500 closed-ended questions with single, unambiguous, verifiable answers. No essays. No subjectivity. You either know it or you don’t.
Where Ancient Scripts Meet Quantum Chemistry
What makes HLE so hard? Not math alone — GPT-5 solves olympiad problems. Not coding — Codex writes working software. The difficulty lies at the intersection of deep expertise and rare knowledge.
Tung Nguyen from Texas A&M authored 73 questions — the second-highest individual count, mostly in math and computer science. «Intelligence isn’t just about pattern recognition, ” he says. „It’s about depth, context, and specialized expertise.“
A typical HLE question demands three things at once: a fact known to a few hundred people worldwide, a reasoning chain that crosses disciplinary boundaries, and a precise, verifiable answer. None of these steps can be completed by searching the web — because the answers don’t exist in indexed form.
The Scoreboard Nobody Wanted to See
When HLE launched in late 2025, the results startled even pessimists.

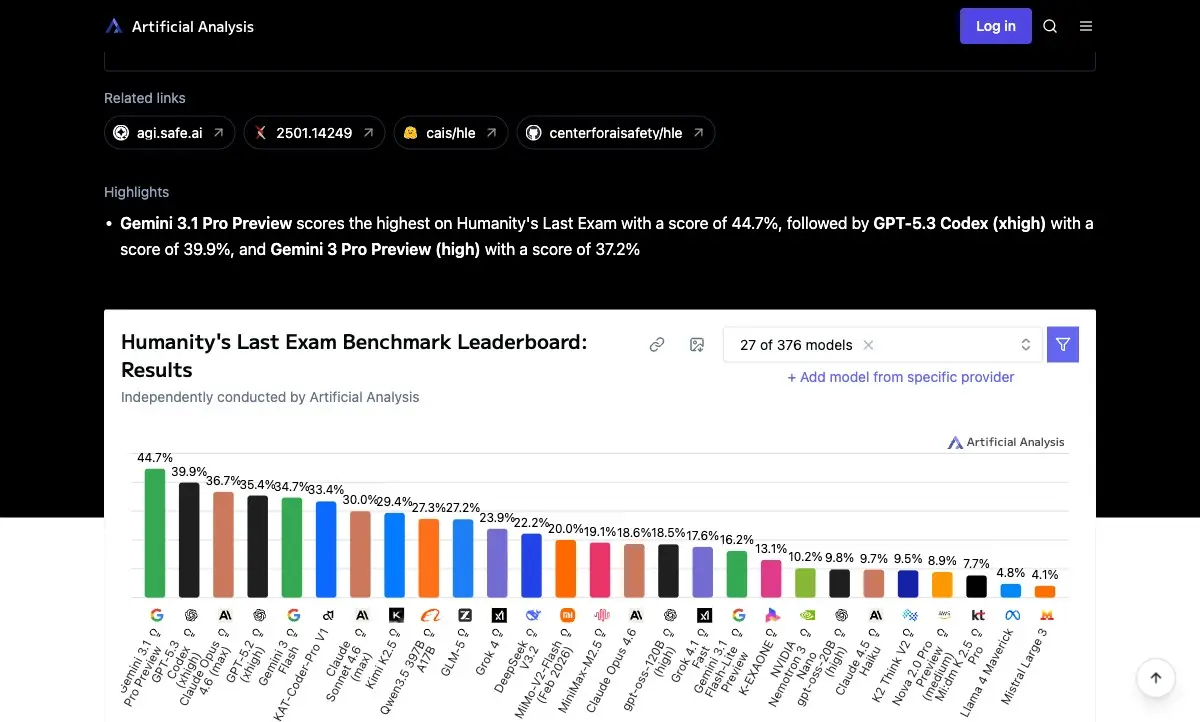
Fig. 1: Model performance on HLE as measured by Artificial Analysis (March 2026). Top score: 44,7% (Gemini 3.1 Pro Preview). Early models scored under 10%. Source: Artificial Analysis
The first contenders — GPT-4o at 2,7% and Claude 3.5 Sonnet at 4,1% — performed worse than educated guessing on a multiple-choice exam. Even o1, OpenAI’s dedicated reasoning model, managed only 8%. Human domain experts scored roughly 90% on those same questions.
By March 2026, newer models closed some of the gap. Gemini 3.1 Pro Preview hit 44,7%. GPT-5.3 Codex reached 39,9%. Still a failing grade by any standard — and remember, each question was specifically designed to stump every model that existed when the test was assembled.
Three Blind Spots the Exam Exposes
HLE attacks three weaknesses simultaneously. The first is rare knowledge. Models train on internet text, but many HLE answers simply don’t exist online. They live in the heads of a few dozen specialists, in undigitized books, in oral academic traditions that never made it to a webpage.
The second is cross-domain reasoning. A question might start in mineralogy, pass through thermodynamics, and end in the history of chemistry. Language models reason well within a single domain but lose the thread at boundaries.
The third is calibration. Models don’t just get answers wrong — they get them wrong confidently. On HLE questions, neural networks frequently assign 90–100% confidence to incorrect answers. This «confident hallucination» pattern appears across every model tested, and HLE exposes it more starkly than any previous benchmark.
The Benchmark’s Own Achilles Heel
HLE hasn’t escaped criticism. An independent analysis by FutureHouse found that roughly 30% of answers in the biology and chemistry sections were incorrect, ambiguous, or poorly formulated. Question authors supplied their own answer keys, and reviewers were given about five minutes to check graduate-level problems. That’s not enough.
The consequence: a model can give a correct answer and still be marked wrong because the key itself is flawed. Critics have called HLE «a total joke» and demanded a fundamental overhaul. The organizers responded by creating curated «gold» subsets (Bio/Chem Gold) where each question-answer pair undergoes verification by multiple experts and separate AI-powered checkers.
A second line of criticism targets the question distribution. A meaningful portion of HLE tests niche academic trivia rather than genuine reasoning — the rarest noble gas in Earth’s crust, or the pronunciation of a specific word in a dead language. That’s not intelligence. That’s memory. And testing memory in a system trained on a text corpus is a questionable exercise.
The study was published in Nature (vol. 649, pp. 1139–1146) in January 2026 and has undergone peer review.
What a Failing Score Actually Tells Us
HLE did something valuable despite its flaws: it made visible a gap that polished demos and saturated benchmarks had hidden. On conventional tests, models score 90%+ and it’s tempting to believe general intelligence is around the corner. HLE shows: the distance is vast.
The benchmark’s own creator predicted it «won’t even live for one year, ” expecting superhuman AI mathematicians by 2025. A year passed. The top score stands at 44,7%. The exam survives — and that survival is itself a data point.
Benchmarks are not exams. They don’t give grades. They measure distance: from where AI stands now to where we expect it to go. HLE measured that distance more honestly than anything before it — even with 30% of its own answer key in question.
References
Original
Related
Related Articles


AI Scans 67,000 Magnets and Finds 25 Rare-Earth-Free Alternatives for EVs
University of New Hampshire physicists built the largest AI-curated magnetic materials database and discovered 25 high-temperature magnets that could replace rare earth elements in electric vehicles.

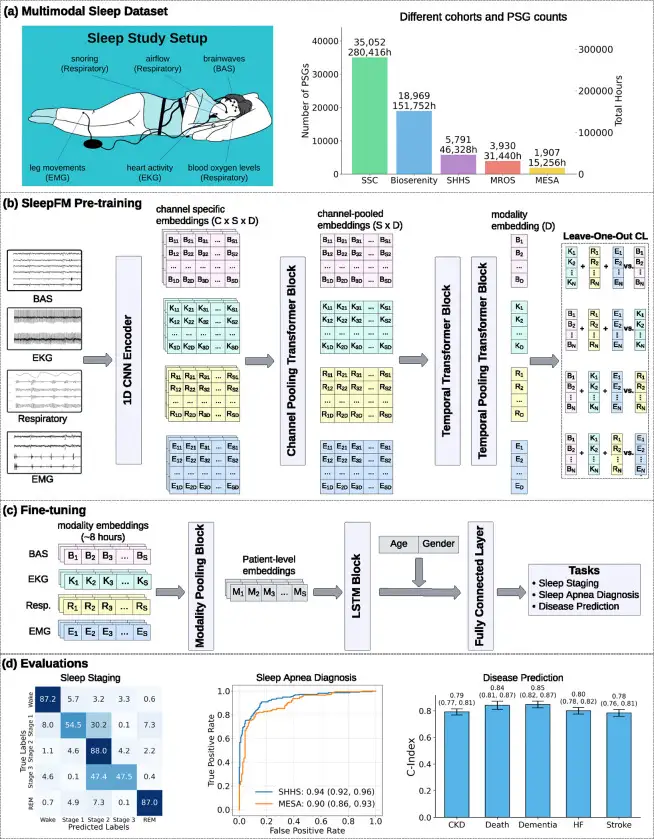
SleepFM: AI Predicts 130 Diseases From One Night of Sleep
Stanford trained a neural network on 585,000 hours of sleep data. It detects Parkinson's, dementia, and cancer years before symptoms appear.


Big Five 2.0: Genes, Stress, and Mortality in Personality Science
Seven key studies from 2024–2025: 254 personality genes, a 'sixth factor,' IL-6 as a mortality biomarker, and how stress reshapes character.